LegalOn Technologies、日本の企業法務における大規模言語モデル(LLM)の性能を評価するベンチマークデータセット「LegalRikai: Open Benchmark」を公開〜主要LLMであるGPT-5、Gemini-2.5-pro、Claude Opus 4.1の分析結果も発表。抽象的な指示への対応力でモデル間に大きな差を検出~
株式会社LegalOn Technologies(本社:東京都渋谷区 代表取締役 執行役員・CEO:角田望、以下LegalOn Technologies)は、日本の企業法務実務における大規模言語モデル(LLM)の性能を評価するベンチマークデータセット「Legal Rikai: Open Benchmark」を公開しました。「Legal Rikai: Open Benchmark」は、LLMによる法改正の説明、法令に準拠した契約書修正、取引先からの要望を契約書へ反映、契約書に潜むリスク検出および修正文生成といった4つのタスクに対する性能を検証することができます。これにより、法務実務に適したモデルの選定を支援し、法務AIにおける透明性の向上と研究の加速を促進します。
また、今回「Legal Rikai: Open Benchmark」を用いて、GPT-5、Gemini-2.5-pro、Claude Opus 4.1といった主要なLLMを分析しました。
▽arXivにて「LegalRikai: Open Benchmark」の概要、各モデルの分析結果を公開。
LegalRikai: Open Benchmark — A Benchmark for Complex Japanese Corporate Legal Tasks
▽Hugging Face Hubにて「LegalRikai: Open Benchmark」のデータソースを公開
https://huggingface.co/datasets/legalontech/Legal-Rikai-Open-Benchmark

■「LegalRikai: Open Benchmark」について
「LegalRikai」*とは、日本の法規制に基づいて大規模言語モデル(LLM)が法的タスクを適切に解決・処理できるかを評価できるベンチマークデータセットです。近年、AIは各業務領域に特化した、専門性の高い業務で活用されつつあります。しかし、企業法務においては、AIがどれだけ「弁護士のように正確」で、「実務で通用する」品質の回答が出せるのか、その評価基準は曖昧でした。この課題を解決するため、当社は2025年3月11日に弁護士による評価基準を取り入れたベンチマークデータセット「LegalRikai」*を開発・発表いたしました。
そしてこのたび、法務AIの分野における透明性の向上と研究の加速を目的に、「LegalRikai」の一部のタスクについてデータセットの設計、評価基準、および実験の設定を「LegalRikai: Open Benchmark」として公開しました。「LegalRikai: Open Benchmark」では、LLMによる法的タスクにおいて以下4つを誰でも検証することが可能です。
①法改正の説明能力
法改正の趣旨と実務への影響を正確に理解し、社内に向けて伝達するための要約能力を検証します。
②法令に準拠した契約書修正
古い法令に対応した契約書を現行法令に対応した契約書に修正できるか検証します。
③契約書へ要望を反映
関係者からの意見や要望を忠実に契約書に反映する能力を検証します。
④契約書に潜むリスク検出および修正文生成
契約書の潜在的リスクを検出し、そのリスクを低減するための修正文案を提案する能力を検証します。
これらのタスクが検証できることで、LLMの知識量だけでなく「実務適合性」を多角的に評価することができます。これにより、AI開発企業や研究機関が、この公開されたデータと基準を用いて、自社のLLMの性能を公正に比較・検証が可能です。加えて、法務AIのベンダーが「LegalRikai: Open Benchmark」を利用することで、より実践的で高品質なモデルを効率的に開発できる環境を構築することができます。
*LegalOn Technologies、 日本の法規制に基づいて大規模言語モデル(LLM)が 法的タスクを適切に解決・処理できるかを 評価できるベンチマークデータセット「LegalRikai」を開発
■GPT-5、Gemini-2.5-pro、Claude Opus 4.1を検証
今回、「LegalRikai: Open Benchmark」を用いて主要なLLMとされるGPT-5、Gemini-2.5-pro、Claude Opus 4.1を検証し、各モデルの得意分野と特徴を分析することができました。論文の内容から、最も複雑性の高いタスクの検証結果をピックアップしてご紹介します。
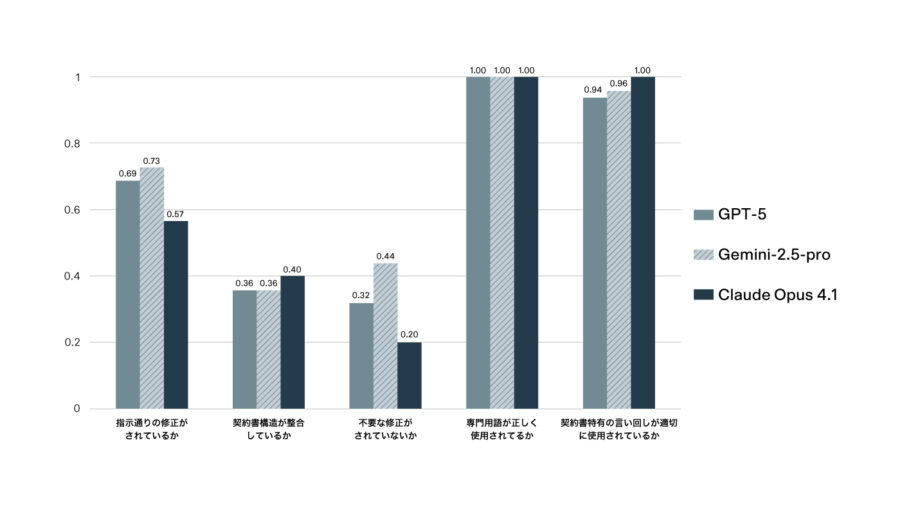
・現行法令に準拠した契約書を出力するタスクにおいて、正確性・体裁・ノイズでモデル特性が明らかに
改正前の法令に準拠した契約書を、改正後の法令に準拠した契約書へと出力するタスクは、以下のフローが必要となり、全タスクの中で複雑性が最も高いタスクに位置しています。
①改正前の法令の把握
②改正前後の差分の把握
③契約書へ影響する改正箇所の特定
④既存契約書の構造と内容の理解
⑤編集が必要な条項の特定と修正
このタスクを各LLMで推論し、当社の法務部門による人手評価を行ったところ、以下の結果となりました。
Gemini-2.5-proは、『指示通りの修正が行われているか』では0.73、『不要な修正がされていないか』では0.44と他モデルよりも高いスコアを記録し、網羅性と正確性に優れていることがわかりました。
Claude Opus 4.1は『契約書構造が整合しているか』で0.40、『契約書特有の言い回しが適切に使用されているか』において1.0と最高スコアを記録し、契約書としての体裁を維持することに長けていることがわかりました。一方で、『不要な修正がされていないか』は0.20と最も低く、指示にない余分な変更を行う傾向が強いことを示しています。
GPT-5は、Gemini-2.5-proとClaude Opus 4.1の両者の中間といった性能結果となりました。
また、全モデルが『専門用語が正しく使用されているか』において最高スコアの1.0を記録しており、専門用語の使用に問題が見られませんでした。
これらの結果は、法務実務においてLLMを選定する際には、単一の総合スコアだけでなく、指示の具体性などのタスクの性質とモデルの得意な側面を考慮する必要があることを強く示しています。上記の他3つのタスクの検証結果については、論文よりご覧いただけます。
▽arXivにて「LegalRikai: Open Benchmark」の概要、各モデルの分析結果を公開。
LegalRikai: Open Benchmark — A Benchmark for Complex Japanese Corporate Legal Tasks
▽Hugging Face Hubにて「LegalRikai: Open Benchmark」のデータソースを公開
https://huggingface.co/datasets/legalontech/Legal-Rikai-Open-Benchmark
LegalOn Technologiesは、これからも「LegalRikai: Open Benchmark」の継続的な改善と検証を通じて、法務AIの進化をリードし、企業がより安全で、より効果的なAIを実装できるよう貢献してまいります。
■「LegalOn: World Leading Legal AI」について( URL:https://www.legalon-cloud.com/ )
「LegalOn: World Leading Legal AI」は、国境を越えて非効率な法務業務を一掃し、お客様の法務チームが思考と決断にフォーカスし、全社の成長を牽引することを可能にします。LegalOn Technologiesの法務コンテンツとAI(エージェント)は、お客様の競争力強化と成長に貢献し、より優れた法務プロセスを通じて、お客様のビジネスを迅速に前進させることを目指します。「LegalOn」には、法務相談やリーガルリサーチ、論点整理、契約書レビュー、契約書作成など、高度かつ複雑な法務業務に対応するAIエージェント「LegalOn Agents」を搭載し、各法務業務を弁護士監修コンテンツや外部情報とも連携しながら自律的に処理し、法務チームを強力にバックアップします。同時に、「LegalOn」を活用するだけで「LegalOn」上にナレッジが自然に蓄積され、AIエージェントによる業務遂行に自然と反映される状態を実現します。
「LegalOn」は法務チームのために開発された「世界水準の法務AI」としてお客様の法務チームを強力にバックアップし続けます。